機械学習
機械学習 [Machine Learning]
機械学習に関して体系的にまとめたマイノートです。今後も随時追加予定です。

尚、本記事内容に関連した Python & scikit-learn ライブラリを用いた実装コード集は、以下の GitHub レポジトリにおいてあります。
目次 [Contents]
- 機械学習の概要 [Overview]
- 全体 MAP 図
- 機械学習の基本的なタスク処理
- 学習の方法、種類
- 教師あり学習 [supervised learning] と教師なし学習 [Unsupervised learning]
- バッチ学習 [batch learning] とオンライン学習 [online learning]
- 強化学習 [reinforcement learning]
- アンサンブル学習 [ensemble learning]
- 機械学習の前処理 [pre processing]
- モデルの評価 [evaluate model]
- 汎化能力 [generalizing capability]
- データの分割手法とモデルの評価
- 学習曲線 [Learning Curve]と検証曲線 [Validation Curve]
- 陽性 [positive]、陰性 [negative] から導かれる各種評価指数(2クラスの識別問題)
- グリッドサーチに [grid search] よるモデルのハイパーパラメータのチューニング
- 情報量基準[Information Criterion]
- 確率モデルと識別関数 [discriminant function]
- 確率モデル(パラメトリックモデル [parametric models]と、ノンパラメトリックモデル [non-parametric models])
- 識別規則 [idification rule]
- ベイスの識別規則 [Bayes's idification rule]
- ベイズの定理 [Bayes' theorem]
- ベイスの識別規則 [Bayes's idification rule]
- 識別クラスの決定 [desicide identification class] と、尤度比(ゆうどひ) [likelihood ratio]
- ベイスの識別規則 [Bayes' identification rule] と誤り率最小化 [minimarize error rate]
- 最小損失基準 [minimum loss standard] に基づくベイズの識別規則 [Bayes' identification rule](損失を考慮に入れたベイズの識別規則)
- 判断の留保(リジェクト) [decision of rejection]
- 使用例 [example]
- 正規分布関数と正規分布から導かれる識別関数
- 最大尤度法 [MLE:maximum likelihood estimation]による確率モデルのパラメータの推定
- 線形判別分析 [LDA : liner discrinant analysis]
- ロジスティクス回帰 [Logistic Regression]
- 最近接法, k-NN 法 [k-nearest neighbor algorithm]
- サポートベクターマシン [SVM : Support Vector Machine]
- 決定木 [Decision Tree]
- アンサンブル学習 [ensemble learning]
- クラスター分析 [Clustering Analysis]
- 【外部リンク】 ニューラルネットワーク [NN :Neural Network]
- 参考文献
概要 [Overview]
■ 機械学習の基本的なタスク処理
機械学習は、大きく分けて以下の3つの問題設定&解決のための手法に分けることが出来る。
■ 学習の方法、種類
◎ バッチ学習 [batch learning] とオンライン学習 [online learning]
☆ バッチ学習 [batch processing]
一定量もしくは、一定期間データを集め、まとめて一括に学習を行う学習方式。
より詳細には、
モデルの重みの更新を、各々のサンプルデータ毎に小刻みに行うでのはなく、トレーニングデータ・セット全てのサンプルに対して、一斉(一度)に行う。(バッチ処理)
最急降下法による学習などが、これに相当する。

☆ オンライン学習 [batch processing]
データを一度に一斉に学習を行うバッチ学習とは異なり、
新しいトレーニングデータが届いた際に、その場でモデルに対し、このサンプルでの追加の学習を随時行う学習方式。
オンライン学習を用いれば、生じた変化に素早く適応させることができる。
応用上において、これが特に役に立つのは、Webアプリケーションの顧客データなどの大量のデータを扱うケースである。
確率的勾配法などがこれに相当する。
◎ 強化学習 [reinforcement learning]
試行錯誤を通じて環境に適応する学習制御の枠組である。
教師有り学習とは異なり、状態入力に対する正しい行動出力を明示的に示す教師データが存在しない。(教師なし学習)
そのかわりに、報酬というスカラーの情報を手がかりに学習するが、報酬にはノイズや遅れがある。
そのため、行動を実行した直後の報酬をみるだけでは学習主体はその行動が正しかっ たかどうかを判断できないという困難を伴うヒューリスティックな手法。
(※ ヒューリスティック:必ず正しい答えを導けるわけではないが、ある程度のレベルで正解に近い解を得ることができる方法。 )

◎ アンサンブル学習 [ensemble learning]
各識別器を組み合わせて使用し、それらの識別器(弱識別器という)の投票結果(単純な多数決 or 重み付け後の多数決等)で最終的な判断を下す学習方法。 様々な識別器を組み合わせて 多様性のある学習 を行うため、汎化性能が高く、又過学習 [overfitting] を起こしにくい。
- 実装コード
- Python & scikit-learn ライブラリを用いた、機械学習における、アンサンブル学習のサンプルコード集。(練習プログラム) github.com
■ 機械学習の前処理 [pre processing]
- 実装コード
- Python & scikit-learn ライブラリを用いた、機械学習における、データの前処理のサンプルコード集。(練習プログラム) github.com
■ 欠損値への対応
◎ 欠損値 NaN を含むデータ

◎ NaN の平均値補完

■ カテゴリデータ(名義 [nominal] 特徴量、順序 [ordinal] 特徴量)の処理
パターン認識は、対象を観測し、識別に有効な特徴を抽出することから始まるが、
観測された特徴は、非数値データとして抽出される定性的特徴 [qualitative feature] と、数値データとして抽出される定量的特徴 [quantitative feature] に分類できる。
定性的特徴と定量的特徴のデータは、更に下図のように型分類できる。

尚、定性的特徴を処理するためには、データの符号化を行う。(例えば、2つのクラスラベルを表すために、"0と1"あるいは"-1と+1"のように符号化する。)
■ データの分割
機械学習モデルの学習を行うためには、入力データとその該当するクラスを記述した学習データが必要になる。
(※教師あり学習 [supervised learning] の場合 )
クラスを指定したデータを教師データといい、
2クラスの場合、出力 y の正負に対応した値
 で表す。
で表す。
クラス数が3つ以上の場合は、クラス数のビット幅を持ったダミー変数表現を用いて、
例えば、
 のように表現する。(このような符号化方式をK対1符号化 [1-of-K coding] という。※尚、Kはクラス数を表している。)
のように表現する。(このような符号化方式をK対1符号化 [1-of-K coding] という。※尚、Kはクラス数を表している。)
そして、入力データと教師データのペアは、以下のように表す。

学習に用いられるすべてのペアの集合を学習データセット [learning data set] と呼び、
 で表す。
で表す。
一方、学習に使用しなかったデータは、テストデータセットとして、
 として、性能評価に使える。
として、性能評価に使える。
◎ 学習データとテストデータの作り方とバイアス、誤り率

学習データセット とテストデータセット は、手元にあるデータを分割して作ることになる。
今、上図のように、
とある識別対象(100円玉など)を、その母集団からN 個用意し、その内、L 個を学習用データに、T 個をテスト用データに使用する場合を考える。
また、識別対象を識別するために d 個の特徴(10円玉の重さ、透磁率など)が用いられているとする。
すると、学習データセット は、L 個の d 次元特徴ベクトルからなる集合
テストデータセット は、T 個の d 次元特徴ベクトルからなる集合となる。
それぞれの特徴ベクトルの d 次元空間内での分布関数を  及び
及び  で表すことにすれば、
で表すことにすれば、
この分布関数から、平均値、分散値などが計算できる!
しかしながら、
学習データセットとテストデータセットは、母集団からランダムに抽出されたものであるが、
その分布関数 及び の平均値や分散値が、母集団  のそれと同じになるとは限らない。
のそれと同じになるとは限らない。
この母集団とのズレをバイアス(偏り)[bias] という。
ここで、学習データセット から算出し、テストデータセット を使用してテストしたときの誤り率を、 で表すことにする。
で表すことにする。
すると、母集団の誤り率(真の誤り率)は、 と表現でき、
と表現でき、
母集団の分布 に従う学習データから算出し、母集団の分布 に従うテスト用データを用いてテストしたときの誤り率を意味する。
また、母集団からサンプリングした学習データをテストデータとして再利用した場合の誤り率を、
再代入誤り率 [resubstitution error] といい、 で表現できる。
で表現できる。
特徴データの変換、特徴量のスケーリング
特徴ベクトル空間 [feature vector space]

特徴ベクトルの変換




特徴ベクトルの正規化(標準化) [normalization/standardization]

使用例

特徴ベクトルの無相関化 [decorrelation]


使用例

特徴データの次元圧縮

- 実装コード
- Python & scikit-learn ライブラリを用いた、主成分分析 [PCA : Principal Component Analysis] による教師なしデータの次元削除、特徴抽出 github.com
- Python & scikit-learn ライブラリを用いた、カーネル主成分分析 [kernelPCA : kernel Principal Component Analysis] による非線形写像と教師なしデータの次元削除、特徴抽出 github.com
主成分分析 [PCA : Principal Component Analysis]

主成分分析(PCA)の分散最大化による定式化


主成分分析(PCA)の誤差最小化による定式化










PCAによる次元の削除

使用例 [example]
PCA による次元の削除の使用例
13×178 次元のワインデータ → 2×124 次元のデータに次元削除(特徴抽出)(※124は分割したトレーニングデータ数)
ワインデータをPCAによる次元削除を行なったデータの散布図。 寄与率と累積寄与率の図より、第1主成分と第2主成分だけで、全体のデータの60%近くを説明できることから、2×124 次元のデータで散布図を図示。この後、この次元削除したデータでクラス識別用のデータに使用する。

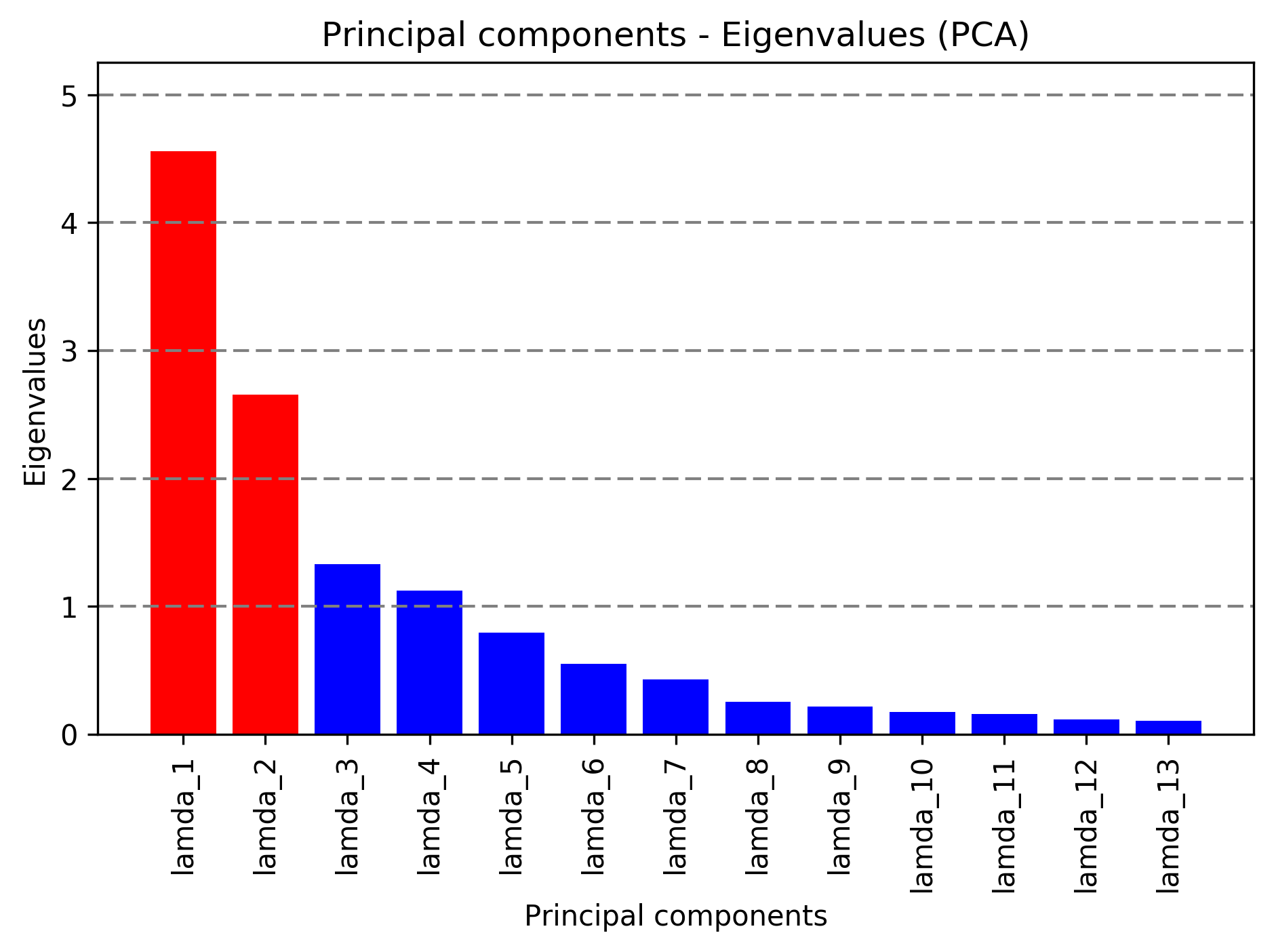
| λ_1 | λ_2 | λ_3 | λ_4 | λ_5 | λ_6 | λ_7 | λ_8 | λ_9 | λ_10 | λ_11 | λ_12 | λ_13 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4.56 | 2.65 | 1.33 | 1.13 | 0.80 | 0.55 | 0.43 | 0.25 | 0.22 | 0.18 | 0.16 | 0.12 | 0.11 |
寄与率(分散の比)[proportion of the variance] / 累積寄与率 [Cumulative contribution rate]

| principal component | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 寄与率 | 0.366 | 0.213 | 0.107 | 0.090 | 0.064 | 0.044 | 0.035 | 0.020 | 0.017 | 0.014 | 0.0125 | 0.009 | 0.0086 |
| 累積寄与率 | 0.366 | 0.578 | 0.685 | 0.775 | 0.839 | 0.883 | 0.918 | 0.938 | 0.955 | 0.970 | 0.982 | 0.991 | 1.000 |
カーネル主成分分析 [kernel PCA : kernel Principal Component Analysis]





使用例 [example]
- kernelPCA による次元の削除の使用例
sklearn.datasets.make_moons( n_samples = 100 )で生成した半月状のデータ(サンプル数:100個)に対し、通常の PCA を適用した結果。上段の図より、通常の PCA では、うまく線形分離可能なテータに変換できていないことが分かる。(※下段の図は、各主成分に対する固有値と寄与率、累積率寄与率の図)尚、第1主成分 PC1 のみに次元削除(特徴抽出)した図は、各クラス(0 or 1)の識別を見やすくするため、上下に少し移動させている。

sklearn.datasets.make_moons( n_samples = 100 )で生成した半月状のデータ(サンプル数:100個)に対し、RBF カーネルをカーネル関数とする、カーネル PCA を適用した結果。上段の図より、RBFカーネルをカーネルとするkernelPCA では、この半月状のデータをうまく線形分離可能な特徴空間に写像出来ていることが分かる。(尚、第1主成分 PC1 のみに次元削除(特徴抽出)した図は、各クラス(0 or 1)の識別を見やすくするため、上下に少し移動させている。) 下段の図は、RBFカーネル関数のカーネル行列(グラム行列)の固有値を、大きい順に 40 個表示した図。カーネル行列の固有値は固有値分解を近似的な数値解析的手法で解いており、0 に近い値の固有値がこれに続いている。
sklearn.datasets.make_circles( n_samples = 1000 )で生成した同心円状のデータ(サンプル数:1000個)に対し、通常の PCA を適用した結果。上段の図より、通常の PCA では、うまく線形分離可能なテータに変換できていないことが分かる。(※下段の図は、各主成分に対する固有値と寄与率、累積率寄与率の図)尚、第1主成分 PC1 のみに次元削除(特徴抽出)した図は、各クラス(0 or 1)の識別を見やすくするため、上下に少し移動させている。
sklearn.datasets.make_circles( n_samples = 1000 )で生成した同心円状のデータ(サンプル数:1000個)に対し、RBF カーネルをカーネル関数とする、カーネル PCA を適用した結果。上段の図より、RBFカーネルをカーネルとするkernelPCA では、この半月状のデータをうまく線形分離可能な特徴空間に写像出来ていることが分かる。(尚、第1主成分 PC1 のみに次元削除(特徴抽出)した図は、各クラス(0 or 1)の識別を見やすくするため、上下に少し移動させている。)



部分空間法 [subspace methods]
部分空間 [sub space]

モデルの評価 [evaluate model]
参考
My GitHub : Yagami360/MachineLearning_Exercises_Python_scikit-learn Python&機械学習ライブラリ scikit-learn の使い方の練習コード集。機械学習の理論解説付き
scikit-learn パイプライン(Pipeline クラス)による機械学習処理フローの効率化、 及び、モデルの汎化性能の各種評価方法(2クラスの識別問題を対象) Yagami360/MachineLearning_Exercises_Python_scikit-learn/MachineLearningPipeline_scikit-learn
汎化能力 [generalizing capability]

モデル選択 [model selection]
「モデル選択」という用語は、チューニングパラメータの”最適な”値を選択する分類問題を指す。

多項式の関数近似での例

【補足】より広義な意味でのモデル選択


バイアス・バリアントトレードオフ [bias-variance trade-off]
多項式の関数近似での例


過学習 [overfitting]
多項式の関数近似での例


正則化 [Regularization] による過学習への対応

L2 正則化 [L2 reguraration](正則化最小2乗法)


L1 正則化による疎な解 [Sparse solution](ほとんどの特徴量の重みが0になるような解)


損失関数 [loss funtions](コスト関数、誤差関数)
損失関数(評価関数、誤差関数)は、モデルの出力と目的値(真の値、教師データ)との差(いいえ変えれば、誤差、距離)を計測する関数であり、モデルの学習に適用されるものである。
ここで、機械学習は、大きく分けて以下の2つの問題設定&解決のための手法に分けることが出来た。 ① 回帰問題の為の手法。(単回帰分析、重回帰分析、等) ② (クラスの)分類問題の為の手法(SVM、k-NN、ロジスティクス回帰、等)
従って、損失関数も同様にして、回帰問題の為の損失関数と、分類問題の為の損失関数が存在することになる。
回帰問題の為の、損失関数(L2正則化、L1正則化)

- L2 正則化の損失関数は、目的値への距離の2乗で表されるので、下に凸な2次関数の形状をしており、 目的値(この場合 0)の近くで急なカーブを描く。 この特性が、損失関数と扱う際に優れているのが特徴である。
- L1 正則化の損失関数は、目的値への距離の絶対値で表される損失関数である。 その為、目的値(この場合 0)からのズレが大きくなっても(ズレの大きなに関わらず)、その傾き(勾配)は一定である。 その為、L1 正則化は L2 正則化よりも、外れ値にうまく対応するケースが多いのが特徴である。 又、目的値(この場合 0)にて、関数が連続でないために、対応するアルゴリズムがうまく収束しないケースが存在することに注意が必要となる。
分類問題の為の、損失関数
記載中...
データの分割手法とモデルの評価

手元にあるデータを学習用とテスト用に分割する代表的な方法、及びモデルの評価法には、以下のような手法がある。
ホールド・アウト法 [holdout method]

交差確認法 [cross validation method] (=交差検証法、交差妥当化法)


1つ抜き法 [leave-one-out method] (=ジャックナイフ法)
記載中...
ブートストラップ法 [bootstrap method]


学習曲線 [Learning Curve]と検証曲線 [Validation Curve]
記載中...
陽性 [positive]、陰性 [negative] から導かれる各種評価指数(2クラスの識別問題)
混同行列、適合率、再現率、F1スコア
ROC曲線(受信者動作特性曲線)[receiver operator characteristics curve]




ROC曲線下面積 [AUC: area under ROC curve]

ROC曲線と損失直線(最適な動作点の選択)




グリッドサーチ [grid search] によるハイパーパラメータのチューニング
記載中...
確率モデルと識別関数 [discriminant function]
確率モデル(パラメトリックモデル [parametric models]と、ノンパラメトリックモデル [non-parametric models])

識別規則 [idification rule]

① 事後確率 [posterior probability] によるクラス分類法

② 距離 [distance] によるクラス分類法

③ 関数値 [function value] によるクラス分類法

④ 決定木 [decision tree] によるクラス分類法

ベイスの識別規則 [Bayes's idification rule]
ベイズの定理 [Bayes' theorem]



ベイスの識別規則 [Bayes's idification rule]


識別クラスの決定 [desicide identification class] と、尤度比(ゆうどひ) [likelihood ratio]

ベイスの識別規則 [Bayes' identification rule] と誤り率最小化 [minimarize error rate]



最小損失基準 [minimum loss standard] に基づくベイズの識別規則 [Bayes' identification rule](損失を考慮に入れたベイズの識別規則)




判断の留保(リジェクト) [decision of rejection]



使用例 [Examples]


正規分布関数と正規分布から導かれる識別関数






使用例 [example]

最大尤度法 [MLE:maximum likelihood estimation]による確率モデルのパラメータの推定

線形判別分析 [LDA : liner discrinant analysis]
線形識別関数 [liner discriminant function] でのクラス識別<識別規則>

超平面 [hyper plane] の方程式


多クラスの識別問題への拡張



最小2乗法によるパラメータ推定



使用例 [Example]

線形判別分析 [LDA : liner discrinant analysis] によるパラメータ推定




判別分析法



使用例 [Examples]



ロジスティクス回帰 [Logistic Regression]
ロジスティック回帰 [logistic regression] による識別関数のパラメータ推定


ロジスティック回帰モデル



最尤度法によるロジスティック回帰モデル(確率モデル<ノンパラメトリックモデル>)のパラメータ推定 [MLE:maximum-likelihood estimation]



L2正則化による過学習への対応(評価関数への正則化項の追加)

ロジスティック回帰 [logistic regression] による識別問題の多クラスへの拡張と、非線形変換 [no-liner transformation]、ガウス核関数 [Gaussian kernel function]



使用例 [Examples]








参考
My GitHub : Yagami360/MachineLearning_Exercises_Python_scikit-learn Python&機械学習ライブラリ scikit-learn の使い方の練習コード集。機械学習の理論解説付き
ロジスティクス回帰の練習コード。scikit-learn ライブラリを使用。 MachineLearning_Exercises_Python_scikit-learn/LogisticRegression_scikit-learn
最近接法, k-NN 法 [k-nearest neighbor algorithm]

最近傍法 [nearest neighbor algorithm] とボロノイ境界 [Voronoi diagram]

ボロノイ図 [Voronoi diagram]



鋳型の数と識別性能

使用例 [Examples]


k最近傍法(k-NN法)[k-nearest neighbor algorithm]




k-NN法 [k-nearest neighbor algorithm] での誤り発生のメカニズムとベイズ誤り率との関係


k-NN法の計算量とその低減法
記載中...
使用例 [Examples]

参考
My GitHub : Yagami360/MachineLearning_Exercises_Python_scikit-learn Python&機械学習ライブラリ scikit-learn の使い方の練習コード集。機械学習の理論解説付き
k-NN 法の練習コード。scikit-learn ライブラリを使用。 MachineLearning_Exercises_Python_scikit-learn/kNN_scikit-learn
サポートベクターマシン [SVM : Support Vector Machine]

マージン [margin] とマージン最大化について

サポートベクターマシン(SVM)[support vector machine] の導出

線形分離可能な系における最適識別超平面とサポートベクトルによるマージン最大化 [margin maximization]


マージン最大化 [margin maximization] と不等式制約条件凸最適化問題(数理計画法)[unconstrained convex optimization]




KTT [Karush-Kuhn-Tucker] 条件

データの分布が線形分離不可能な系への拡張(スラック変数の導入)とソフトマージン識別器(C-SVM)、その最適化問題





サポートベクターマシンにおける非線形特徴写像 <カーネル関数、カーネル法 [kernel method] 、カーネルトリック [kernel trick]>



多項式カーネル


動径基底関数カーネル(RBFカーネル)[radial bases function kernel]


使用例 [Examples]





v-サポートベクターマシン
記載中...
参考
My GitHub : Yagami360/MachineLearning_Exercises_Python_scikit-learn Python&機械学習ライブラリ scikit-learn の使い方の練習コード集。機械学習の理論解説付き
サポートベクターマシンのサンプルコード集。(練習プログラム)scikit-learn ライブラリを使用。 MachineLearning_Exercises_Python_scikit-learn/SVM_scikit-learn
決定木 [Decision Tree]


【補足】決定木に関しての諸定義(グラフ理論)

【補足】決定木のノードの特徴空間のクラス分け(各種ノードの確率と識別クラス)


ノードの分割規則と不純度 [purity]

不純度 [purity] を表す代表的な関数

木の剪定(せんてい) [pruning] アルゴリズムと過学習対策

木の剪定アルゴリズム



使用例 [Examples]



参考
My GitHub : Yagami360/MachineLearning_Exercises_Python_scikit-learn Python&機械学習ライブラリ scikit-learn の使い方の練習コード集。機械学習の理論解説付き
決定木のサンプルコード集。(練習プログラム)scikit-learn ライブラリを使用。 MachineLearning_Exercises_Python_scikit-learn/DecisionTree_scikit-learn
アンサンブル学習 [ensemble learning]
各識別器を組み合わせて使用し、それらの識別器(弱識別器という)の投票結果(単純な多数決 or 重み付け後の多数決等)で最終的な判断を下す学習方法。 様々な識別器を組み合わせて 多様性のある学習 を行うため、汎化性能が高く、又過学習 [overfitting] を起こしにくい。
参考
My GitHub : Yagami360/MachineLearning_Exercises_Python_scikit-learn Python&機械学習ライブラリ scikit-learn の使い方の練習コード集。機械学習の理論解説付き
アンサンブル学習のサンプルコード集。(練習プログラム)scikit-learn ライブラリを使用。 MachineLearning_Exercises_Python_scikit-learn/EnsembleLearning_scikit-learn
混合モデル [mixed model]

混合モデルによるモデル多様体の拡張

混合正規分布モデル [GMM : Gaussian Mixture Model]

混合正規分布モデルの幾何学的観点





EM アルゴリズム [expectation–maximization algorithm]

EM アルゴリズムの適用例




EM アルゴリズムの幾何学的解釈




ブースティング [Boosting]、アダブースト [AdaBoost]

アダブースト [AdaBoost]


アダブーストの学習アルゴリズムの導出



アダブーストの幾何学的解釈





バギング [Bagging]


バギングの幾何学的解釈

ランダムフォレスト [Random Forests]

ランダムフォレストの学習アルゴリズム




ランダムフォレスト固有のデータ解析(OBBランダムフォレスト固有のデータ解析(OOB 誤り率 [ out-of-bag error rate]、特徴の重要さ)



参考
My GitHub : Yagami360/MachineLearning_Exercises_Python_scikit-learn Python&機械学習ライブラリ scikit-learn の使い方の練習コード集。機械学習の理論解説付き
ランダムフォレストのサンプルコード集。(練習プログラム)scikit-learn ライブラリを使用。 MachineLearning_Exercises_Python_scikit-learn/EnsembleLearning_scikit-learn
クラスター分析 [Clustering Analysis]
標本化 [sapling] と量子化 [quantization]

ベクトル量子化 [QV : quantization vector]

k-means 法

学習ベクトル量子化 [LQV : leaning quantization vector]

参考
My GitHub : Yagami360/MachineLearning_Exercises_Python_scikit-learn Python&機械学習ライブラリ scikit-learn の使い方の練習コード集。機械学習の理論解説付き
クラスター分析のサンプルコード集。(練習プログラム)。scikit-learn ライブラリを使用。 MachineLearning_Exercises_Python_scikit-learn/ClusteringAnalysis_scikit-learn
参考文献

- 作者: 平井有三
- 出版社/メーカー: 森北出版
- 発売日: 2012/07/31
- メディア: 単行本(ソフトカバー)
- 購入: 1人 クリック: 7回
- この商品を含むブログ (5件) を見る

- 作者: C.M.ビショップ,元田浩,栗田多喜夫,樋口知之,松本裕治,村田昇
- 出版社/メーカー: 丸善出版
- 発売日: 2012/04/05
- メディア: 単行本(ソフトカバー)
- 購入: 6人 クリック: 33回
- この商品を含むブログ (20件) を見る
")
- 作者: C.M.ビショップ,元田浩,栗田多喜夫,樋口知之,松本裕治,村田昇
- 出版社/メーカー: 丸善出版
- 発売日: 2012/02/29
- メディア: 単行本
- 購入: 6人 クリック: 14回
- この商品を含むブログを見る

パターン認識と機械学習の学習―ベイズ理論に負けないための数学
- 作者: 光成滋生
- 出版社/メーカー: 暗黒通信団
- 発売日: 2017/07/01
- メディア: 単行本
- この商品を含むブログを見る
")
情報理論の基礎―情報と学習の直観的理解のために (SGC Books)
- 作者: 村田昇
- 出版社/メーカー: サイエンス社
- 発売日: 2008/08/01
- メディア: 単行本
- 購入: 4人 クリック: 11回
- この商品を含むブログ (7件) を見る
")
- 作者: 高村大也,奥村学
- 出版社/メーカー: コロナ社
- 発売日: 2010/07/01
- メディア: 単行本
- 購入: 13人 クリック: 235回
- この商品を含むブログ (42件) を見る
")
- 作者: 尾畑伸明
- 出版社/メーカー: サイエンス社
- 発売日: 2008/08/01
- メディア: 単行本
- クリック: 1回
- この商品を含むブログを見る

Python機械学習プログラミング 達人データサイエンティストによる理論と実践 impress top gearシリーズ
- 作者: Sebastian Raschka,株式会社クイープ,福島真太朗
- 出版社/メーカー: インプレス
- 発売日: 2016/06/30
- メディア: Kindle版
- この商品を含むブログ (4件) を見る

Excelで学ぶ多変量解析―資料に隠れた大切な関係は多変量解析を駆使してあぶり出す!
- 作者: 涌井良幸,涌井貞美
- 出版社/メーカー: ナツメ社
- 発売日: 2005/07/01
- メディア: 単行本
- 購入: 2人 クリック: 4回
- この商品を含むブログ (2件) を見る
")
深層学習 Deep Learning (監修:人工知能学会)
- 作者: 麻生英樹,安田宗樹,前田新一,岡野原大輔,岡谷貴之,久保陽太郎,ボレガラダヌシカ,人工知能学会,神嶌敏弘
- 出版社/メーカー: 近代科学社
- 発売日: 2015/11/05
- メディア: 単行本
- この商品を含むブログ (2件) を見る
![複素ニューラルネットワーク(第2版) 2016年 06 月号 [雑誌]](https://images-fe.ssl-images-amazon.com/images/I/51hprPG9z8L._SL160_.jpg "複素ニューラルネットワーク(第2版) 2016年 06 月号 [雑誌]")
複素ニューラルネットワーク(第2版) 2016年 06 月号 [雑誌]
- 作者: 廣瀬明
- 出版社/メーカー: サイエンス社
- 発売日: 2016/06/21
- メディア: 雑誌
- この商品を含むブログを見る
")
TensorFlow機械学習クックブック Pythonベースの活用レシピ60+ (impress top gear)
- 作者: Nick McClure,株式会社クイープ
- 出版社/メーカー: インプレス
- 発売日: 2017/08/14
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (1件) を見る